2020/3/8 追記: model-zoo(https://github.com/FluxML/model-zoo) にDCGANのモデルが入りました。
2019/11/29にJuliaの機械学習ライブラリFlux.jlのv0.10.0がリリースされた。 もともとv0.9.0でDCGANのMNISTデータセットから手書き文字画像生成モデルを作成して、今回の変更に合わせてv0.10.0で動かしたのだが、 ここに至るまで色々と苦戦したので、v0.10.0の主な変更点や、自分がつまづいた点を書いておく。
実装はGitHubのリポジトリ matsueushi/fluxjl-gan を見てほしい。
環境はGCPのn1-standard-8 + 1 x NVIDIA Tesla K80で、Ubuntu 18.04, Juliaのバージョンは1.3.0を利用。
Dockerで環境構築(GPU)
GPUが使えるJuliaのオフィシャルなDocker imageは 現在(2019/12/1)存在しないと思われる。 配布されているようです
(ひっそり CUDA と Julia が同梱されたコンテナイメージも配布されていたりします…… https://t.co/LE1ducHlWE )(姑息な宣伝) https://t.co/VbS7xcYTTV
— やまさき (@yama_k_1101) December 2, 2019
このあたり、GPUのDockerイメージ が利用できるTensorflowが羨ましく感じられる部分ではある。
JuliaGPUのDockerイメージ JuliaGPU/docker はメンテナンスされていないので、nvidia/cuda のイメージをベースに、Juliaのインストール部分は docker-library/julia を参考にDockerfileを作成。
# Dockerfile Julia 1.3.0 + CUDA for Flux.jl
ARG CUDA=10.0
ARG UBUNTU_VERSION=18.04
FROM nvidia/cuda:${CUDA}-cudnn7-devel-ubuntu${UBUNTU_VERSION}
ENV JULIA_PATH=/usr/local/julia
ENV PATH=$JULIA_PATH/bin:$PATH
ENV JULIA_TAR_ARCH=x86_64
ENV JULIA_DIR_ARCH=x64
ENV JULIA_GPG=3673DF529D9049477F76B37566E3C7DC03D6E495
ENV JULIA_VERSION=1.3.0
ENV JULIA_SHA256=9ec9e8076f65bef9ba1fb3c58037743c5abb3b53d845b827e44a37e7bcacffe8
# Based on https://github.com/docker-library/julia
# Copyright (c) 2014 Docker, Inc.
# Released under the MIT license
# https://opensource.org/licenses/mit-license.php
RUN set -eux; \
apt-get update; \
apt-get install -y --no-install-recommends curl gnupg dirmngr; \
rm -rf /var/lib/apt/lists/*; \
\
folder="$(echo "$JULIA_VERSION" | cut -d. -f1-2)"; \
julia_tar_url="https://julialang-s3.julialang.org/bin/linux/${JULIA_DIR_ARCH}/${folder}/julia-${JULIA_VERSION}-linux-${JULIA_TAR_ARCH}.tar.gz"; \
curl -fL -o julia.tar.gz.asc "${julia_tar_url}.asc"; \
curl -fL -o julia.tar.gz "${julia_tar_url}"; \
\
echo "${JULIA_SHA256} *julia.tar.gz" | sha256sum -c -; \
\
export GNUPGHOME="$(mktemp -d)"; \
gpg --batch --keyserver ha.pool.sks-keyservers.net --recv-keys "$JULIA_GPG"; \
gpg --batch --verify julia.tar.gz.asc julia.tar.gz; \
command -v gpgconf > /dev/null && gpgconf --kill all; \
rm -rf "$GNUPGHOME" julia.tar.gz.asc; \
\
mkdir "$JULIA_PATH"; \
tar -xzf julia.tar.gz -C "$JULIA_PATH" --strip-components 1; \
rm julia.tar.gz; \
\
# smoke test
julia --version
# install packages
RUN julia -e 'import Pkg; \
Pkg.add([ \
"BSON", \
"Distributions", \
"HDF5", \
"JLD", \
"FileIO", \
"ImageMagick", \
"Images", \
]); \
Pkg.add([ \
Pkg.PackageSpec(name="Flux", version="0.10"), \
]); \
using BSON, Distributions, HDF5, JLD, FileIO, ImageMagick, Images, Flux'
CMD ["julia"]
CUDAが動く Julia の深層学習フレームワーク Flux.jl の環境構築をDockerで行う. でもっと丁寧に説明されていた(こっちだとソースからビルドしている)。
v0.9.0ではLoadError: LoadError: UndefVarError: libcudnn not defined #918 などのエラーが発生しCuArrays.jlをv1.3に下げる必要があったのだが、v0.10.0ではそのような心配はないのでいいですね。
DCGANのモデル作成
GANの仕組み自体の説明は
はじめてのGAN,
GANについて概念から実装まで ~DCGANによるキルミーベイベー生成~,
今さら聞けないGAN(1) 基本構造の理解,
などを参照してほしい。(自分も勉強中です……)
Fluxには FluxML/model-zoo という実装を集めたレポジトリが存在し、 v0.9.0で実装する際にはGANに関係したプルリクエスト GAN models #47, Added Condtional GAN and DCGAN tutorial #111 が非常に有用だった。
しかしながら、後にも触れるが、v0.10.0で、デフォルトの自動微分エンジンをTrackerからZygote.jlに変える大きな変更 がマージされたので、 そのままコピペしただけでは動かないと思われるため要注意。
ネットワーク、ロス関数の構成は TensorflowのDCGANチュートリアル を参考にした。
noise_dim = 100
channels = 1
generator = Chain(
Dense(noise_dim, 7 * 7 * 256; initW = glorot_normal),
BatchNorm(7 * 7 * 256, relu),
x->reshape(x, 7, 7, 256, :),
ConvTranspose((5, 5), 256 => 128; init = glorot_normal, stride = 1, pad = 2),
BatchNorm(128, relu),
ConvTranspose((4, 4), 128 => 64; init = glorot_normal, stride = 2, pad = 1),
BatchNorm(64, relu),
ConvTranspose((4, 4), 64 => channels, tanh; init = glorot_normal, stride = 2, pad = 1),
) |> gpu
discriminator = Chain(
Conv((4, 4), channels => 64, leakyrelu; init = glorot_normal, stride = 2, pad = 1),
Dropout(0.25),
Conv((4, 4), 64 => 128, leakyrelu; init = glorot_normal, stride = 2, pad = 1),
Dropout(0.25),
x->reshape(x, 7 * 7 * 128, :),
Dense(7 * 7 * 128, 1; initW = glorot_normal)) |> gpu
function generator_loss(fake_output)
loss = mean(logitbinarycrossentropy.(fake_output, 1f0))
return loss
end
function discriminator_loss(real_output, fake_output)
real_loss = mean(logitbinarycrossentropy.(real_output, 1f0))
fake_loss = mean(logitbinarycrossentropy.(fake_output, 0f0))
loss = 0.5f0 * (real_loss + fake_loss)
return loss
end
GANのdiscriminatorは、オリジナルの画像と、Generatorが生成したフェイクの画像を見分ける役割(二値分類)のため、出力層の活性化関数がシグモイド関数、ロス関数がbinarycrossentropyである実装が多いが、 今回はTensorflowの実装同様、出力層には活性化関数を適用せず(恒等写像), ロス関数にlogitbinarycrossentropyを用いた。
シグモイド関数を\( \sigma \) とすると、
\( \text{binarycrossentropy}(\hat{y}, y) = -y \log \hat{y} - (1 - y) \log(1 - \hat{y}), \\ \text{logitbinarycrossentropy}(\hat{z}, y) = (1 - y) \log \hat{y} - \log(\sigma(\hat{z})) \)
だから、(\( y = 0, 1 \) を代入して確かめることで)
\( \text{binarycrossentropy}(\sigma(\hat{z}), y) = \text{logitbinarycrossentropy}(\hat{z}, y) \)
だから数式上では同じ値になる。 しかし、シグモイド関数を適用する前の値が大きい場合、適用後の値は極めて1に近くなるため、binarycrossentropyの計算中に桁落ちが発生してしまい本来の値からの誤差が大きくなり、勾配の値もおかしくなる。 そのため、logitbinarycrossentropyを使ったほうが計算が安定するようである(実験はしてません、ごめんなさい)。 Numerical issues for (logit)binarycrossentropy #914
v0.9.0では binarycrossentropy と logitbinarycrossentropy はCUDA環境で動かなかったがv0.10.0では修正されている。
このあたりを試していた時、masterブランチで binarycrossetnropy は直っていたのに logitbinarycrossentropy は未修正だったので、
初めてFlux.jlにPull resuestを投げて取り込んでもらった。
DiscriminatorとGeneratorのtrain関数は下のように書ける。 細かい部分はリポジトリ参照
function train_discriminator!(dcgan::DCGAN, batch::AbstractArray{Float32, 4})
noise = randn(Float32, dcgan.noise_dim, dcgan.batch_size) |> gpu
fake_input = dcgan.generator(noise)
loss(m) = discriminator_loss(m(batch), m(fake_input))
disc_grad = gradient(()->loss(dcgan.discriminator), Flux.params(dcgan.discriminator))
update!(dcgan.discriminator_optimizer, Flux.params(dcgan.discriminator), disc_grad)
return loss(dcgan.discriminator)
end
function train_generator!(dcgan::DCGAN, batch::AbstractArray{Float32, 4})
noise = randn(Float32, dcgan.noise_dim, dcgan.batch_size) |> gpu
loss(m) = generator_loss(dcgan.discriminator(m(noise)))
gen_grad = gradient(()->loss(dcgan.generator), Flux.params(dcgan.generator))
update!(dcgan.generator_optimizer, Flux.params(dcgan.generator), gen_grad)
return loss(dcgan.generator)
end
Tracker から Zygote.jl への変更
using Zygote #669 のマージにより自動微分のバックエンドがTrackerからZygote.jlに変更された。 Trackerで書かれたモデルは、Zygote.jlに合わせて多少書き直す必要がある。
型の変更
gradient を取った時に返ってくる型が変わった。
v0.9.0
julia> using Flux.Tracker: gradient
julia> f(x) = 3x^2 + 2x + 1;
julia> gr = gradient(f, 2.0)
(14.0 (tracked),)
julia> typeof(gr)
Tuple{Tracker.TrackedReal{Float64}}
v0.10.0
julia> f(x) = 3x^2 + 2x + 1;
julia> gr = gradient(f, 2.0)
(14.0,)
julia> typeof(gr)
Tuple{Float64}
この変更で Tracker.data や .data で TrackerArray や TrackerReal などでラップされた型からデータを取り出す必要がなくなって便利になった。
gradientの書き方
Zygote.jl のリファレンス には Tracker.gradient を単に Zygote.gradient に置き換えれば良いと書いてあるが、
自分の場合はTrackerで取れた微分がZygoteにバックエンドが変わって取れなくなった。
Trackerでは微分を取るときに
noise = randn(Float32, 100, 10)
fake_input = generator(noise)
fake_output = discriminator(fake_input)
loss = sum(fake_output)
gen_grad = gradient(()->loss, Flux.params(generator))
このような書き方もできた。model-zooのPull RequestのDCGANのコードもこのような形式で書いてある。
v0.9.0
julia> gen_grad.grads
IdDict{Any,Any} with 14 entries:
Tracked{Array{Float32,1}}(0x00000000, … => Float32[0.0456388, -0.00530366, -0.0689154, 0.0356684, 0.033944, 0.0469224, 0…
Tracked{Array{Float32,4}}(0x00000000, … => Float32[-0.0663779 0.470391 0.0135268 0.169848; -0.265991 0.113839 -0.297718 …
Tracked{Array{Float32,1}}(0x00000000, … => Float32[-1.0491] (tracked)
Tracked{Array{Float32,1}}(0x00000000, … => Float32[0.0448993, -0.0436305, -0.0396288, -0.0178894, 0.0191187, 0.0322982, …
Tracked{Array{Float32,1}}(0x00000000, … => Float32[3.05707e-7, -6.56961e-7, -1.86265e-7, 6.1249e-8, 3.40864e-7, 3.57977e…
Tracked{Array{Float32,1}}(0x00000000, … => Float32[-2.31666e-8, -1.72295e-7, 4.83415e-8, 2.7474e-8, 2.61934e-8, -9.76142…
Tracked{Array{Float32,1}}(0x00000000, … => Float32[-0.257108, -1.30009, 0.643118, -0.70479, -0.0380322, 0.047996, 0.1616…
Tracked{Array{Float32,1}}(0x00000000, … => Float32[-1.68035, -1.09166, -1.92644, 0.398565, 0.342392, -0.541331, 0.957729…
Tracked{Array{Float32,1}}(0x00000000, … => Float32[-0.34392, -1.29767, 0.489044, -0.76697, -0.265278, 0.834581, 0.20901,…
Tracked{Array{Float32,1}}(0x00000000, … => Float32[-1.86325, -1.0232, -2.0715, -0.0989702, 0.453471, -0.632238, 1.33671,…
Tracked{Array{Float32,4}}(0x00000000, … => Float32[0.161715 0.358326 1.0731 1.53449; 1.10473 0.652393 -0.844213 0.973572…
Tracked{Array{Float32,4}}(0x00000000, … => Float32[-0.107908 0.042381 … -0.0503733 -0.0570333; 0.141959 -0.0503319 … -0.…
Tracked{Array{Float32,2}}(0x00000000, … => Float32[-0.210451 -0.383133 … -0.441269 -0.122698; 0.0191366 -0.273669 … -0.1…
Tracked{Array{Float32,1}}(0x00000000, … => Float32[0.0, -2.23517e-8, 2.6077e-8, 0.0, 2.00234e-8, -9.31323e-9, -2.98023e-…
一方、v0.10.0では
julia> gen_grad.grads
IdDict{Any,Any} with 14 entries:
Float32[0.0396942 0.00191599 0.0301089 0.00723371; 0.0816196 0.036961 0.0352632 0.0343… => nothing
Float32[0.0] => nothing
Float32[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 … 1.0, 1.0, 1.0, 1.0, 1.0, … => nothing
Float32[-0.0002127 0.0137428 … -0.0121552 0.0268332; -0.0131425 -0.00983153 … -0.02382… => nothing
Float32[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 … 1.0, 1.0, 1.0, 1.0, 1.0, … => nothing
Float32[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0 … 0.0, 0.0, 0.0, 0.0, 0.0, … => nothing
Float32[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0 … 0.0, 0.0, 0.0, 0.0, 0.0, … => nothing
Float32[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0 … 0.0, 0.0, 0.0, 0.0, 0.0, … => nothing
Float32[0.0171712 0.00370337 0.0333522 -0.0189711; 0.0416152 -0.0110209 0.0113975 -0.0… => nothing
Float32[-0.0109217 0.0165013 … -0.0128005 0.000112204; -0.00316031 -0.0308092 … -0.011… => nothing
Float32[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0 … 0.0, 0.0, 0.0, 0.0, 0.0, … => nothing
Float32[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0 … 0.0, 0.0, 0.0, 0.0, 0.0, … => nothing
Float32[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0 … 0.0, 0.0, 0.0, 0.0, 0.0, … => nothing
Float32[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 … 1.0, 1.0, 1.0, 1.0, 1.0, … => nothing
微分が nothing になってしまう。自分は、下のように書き換えた。
noise = randn(Float32, 100, 10)
loss(m) = sum(discriminator(m(noise)))
gen_grad = gradient(()->loss(generator), Flux.params(generator))
julia> gen_grad.grads
IdDict{Any,Any} with 23 entries:
RefValue{typeof(^)}(^) => RefValue{Any}((x = nothing,))
Float32[0.0396942 0.00191599 0.… => Float32[-0.136635 -0.1123 -0.0335189 -0.108103; -0.0265187 -0…
RefValue{Val{2}}(Val{2}()) => RefValue{Any}((x = nothing,))
Float32[0.0, 0.0, 0.0, 0.0, 0.0… => [-2.7719e-10, 3.03544e-11, 2.1797e-10, 2.24403e-10, 2.26078e-…
RefValue{typeof(^)}(^) => RefValue{Any}((x = nothing,))
RefValue{Val{2}}(Val{2}()) => RefValue{Any}((x = nothing,))
Float32[-0.0109217 0.0165013 … … => [-0.00735242 0.000570209 … 0.00351829 0.0103457; 0.0116238 -0…
Float32[0.0, 0.0, 0.0, 0.0, 0.0… => AbstractFloat[0.00270601, -0.0176082, 0.00565182, 0.0125242, …
BatchNorm(128, λ = relu) => RefValue{Any}((λ = nothing, β = AbstractFloat[0.00270601, -0.…
RefValue{Val{2}}(Val{2}()) => RefValue{Any}((x = nothing,))
RefValue{typeof(^)}(^) => RefValue{Any}((x = nothing,))
Float32[1.0, 1.0, 1.0, 1.0, 1.0… => AbstractFloat[-0.00987214, -0.0315625, 0.0199244, 0.0148943, …
Float32[1.0, 1.0, 1.0, 1.0, 1.0… => AbstractFloat[0.00182929, 0.00162896, 0.00011289, 0.00182924,…
Float32[-0.0002127 0.0137428 … … => Float32[0.00630109 0.0134955 … 0.0117517 0.000913039; -0.0059…
Float32[1.0, 1.0, 1.0, 1.0, 1.0… => AbstractFloat[-0.0303094, -0.028408, 0.0697083, -0.00634472, …
Float32[0.0, 0.0, 0.0, 0.0, 0.0… => AbstractFloat[-0.0158277, -0.0324276, 0.0719301, 0.00790212, …
Float32[0.0, 0.0, 0.0, 0.0, 0.0… => AbstractFloat[0.00251813, 0.00111592, -0.000486438, 0.0019682…
BatchNorm(64, λ = relu) => RefValue{Any}((λ = nothing, β = AbstractFloat[-0.0158277, -0.…
Float32[0.0171712 0.00370337 0.… => Float32[0.00725331 -0.00364046 -0.000333806 -0.00218348; 0.00…
Float32[0.0] => [-0.426291]
Float32[0.0, 0.0, 0.0, 0.0, 0.0… => [-9.77911e-11, -9.91324e-11, -7.81544e-10, -2.83712e-11, -4.1…
Float32[0.0, 0.0, 0.0, 0.0, 0.0… => [5.82077e-11, -6.54836e-11, -5.45697e-12, -3.49246e-10, -2.25…
BatchNorm(12544, λ = relu) => RefValue{Any}((λ = nothing, β = AbstractFloat[0.00251813, 0.0…
Zygoteでは上のようなimplicit parametersの書き方だけではなく、explicitな書き方 gradient(loss, generator) による微分も可能で、
Zygote.jlの Gradients of ML models にはimplicitな書き方は、
Trackerとの互換性のために残してあると書いてある。
しかしながら、この二つを利用したときに返ってくる型が異なる
julia> typeof(gen_grad)
Zygote.Grads
julia> typeof(gradient(loss, generator))
Tuple{NamedTuple{(:layers,),Tuple{Tuple{NamedTuple{(:W, :b, :σ),Tuple{Array{Float64,2},Array{Float64,1},Nothing}},Base.RefValue{Any},Nothing,NamedTuple{(:σ, :weight, :bias, :stride, :pad, :dilation),Tuple{Nothing,Array{Float32,4},Array{Float64,1},Tuple{Nothing,Nothing},Nothing,Nothing}},Base.RefValue{Any},NamedTuple{(:σ, :weight, :bias, :stride, :pad, :dilation),Tuple{Nothing,Array{Float32,4},Array{Float64,1},Tuple{Nothing,Nothing},Nothing,Nothing}},Base.RefValue{Any},NamedTuple{(:σ, :weight, :bias, :stride, :pad, :dilation),Tuple{Nothing,Array{Float32,4},Array{Float64,1},Tuple{Nothing,Nothing},Nothing,Nothing}}}}}}
ため、update! を使ってモデルパラメータを更新しようとすると、
implicitに書く必要がある。このあたりは、将来的に変わっていく可能性もありそう。
zero_grad! が不要に
DCGANでDiscriminator, Generatorを交互に学習させる時、TrackerではDiscriminatorを学習させた後
zero_grad! 使ってを勾配を0にしないと正しく学習されなかった
https://github.com/FluxML/model-zoo/pull/111#discussion_r341396388
https://github.com/FluxML/model-zoo/pull/111#discussion_r341847127
が、Zygote.jlではその必要がなくなっている。
v0.9.0でこれに気づかず正しく学習が進まず苦戦したので、この修正はありがたい。
v0.9.0
using Flux
d1 = Dense(2, 1)
d2 = Dense(1, 1)
c = Chain(d1, d2)
p1 = params(d1)
p2 = params(d2)
pall = params(c)
x = rand(2, 10)
loss() = sum(c(x))
@info "Case1"
Flux.Tracker.gradient(loss, pall).grads |> values |> println
@info "Case2"
Flux.Tracker.gradient(loss, p1).grads |> values |> println
Flux.Tracker.gradient(loss, p2).grads |> values |> println
# zero out for next case
Flux.Tracker.zero_grad!.(Tracker.grad.(p1))
Flux.Tracker.zero_grad!.(Tracker.grad.(p2))
@info "Case3"
Flux.Tracker.gradient(loss, p1).grads |> values |> println
Flux.Tracker.zero_grad!.(Tracker.grad.(p2))
Flux.Tracker.gradient(loss, p2).grads |> values |> println
Output
[ Info: Case1
Any[Float32[-6.40395 -5.80043] (tracked), Float32[-4.58864] (tracked), Float32[10.0] (tracked), Float32[-15.8992] (tracked)]
[ Info: Case2
Any[Float32[-6.40395 -5.80043] (tracked), Float32[-15.8992] (tracked)]
Any[Float32[-9.17728] (tracked), Float32[20.0] (tracked)]
[ Info: Case3
Any[Float32[-6.40395 -5.80043] (tracked), Float32[-15.8992] (tracked)]
Any[Float32[-4.58864] (tracked), Float32[10.0] (tracked)]
上のCase2のような状況を防ぐために、Case3のように途中にzero_grad!を挟む必要があった。
一方、v0.10.0は
using Flux
d1 = Dense(2, 1)
d2 = Dense(1, 1)
c = Chain(d1, d2)
p1 = params(d1)
p2 = params(d2)
pall = params(c)
x = rand(2, 10)
loss() = sum(c(x))
@info "Case1"
gradient(loss, pall).grads |> values |> println
@info "Case2"
gradient(loss, p1).grads |> values |> println
gradient(loss, p2).grads |> values |> println
Output
[ Info: Case1
Any[Float32[9.715003], Float32[3.7775292 4.41461], Float32[10.0], Float32[-5.8413825]]
[ Info: Case2
Any[Float32[9.715003], Float32[3.7775292 4.41461]]
Any[Float32[10.0], Float32[-5.8413825]]
と正しく計算できる。
Flux.istraining()
testmode! が廃止されて istraining になった。@eval Flux.istraining() = true と @eval Flux.istraining() = false で切り替えると思われるが正直よく分かっていない。
今までモデル単位で設定していたのがグローバルな設定となり、機能性について
Limitation of Flux.istraining() #909
このようなissueが立っているのでここも変更の可能性がありそう。
以下は他に気づいた点。
常にFloat32を使う
これはバージョンは関係ない話で、
Don’t use more precision than you need. には、必ずしも Float64 を使う必要はなく、 Float32 を使えば良いとある。
何も考えずにJuliaで実数型を使うと Float64 になるので、明示的に Float32 を使う意識が必要。
julia> typeof(1.0)
Float64
julia> [1.0, 2.0, 3.0]
3-element Array{Float64,1}:
1.0
2.0
3.0
julia> typeof(1.0f0)
Float32
julia> Float32[1.0, 2.0, 3.0]
3-element Array{Float32,1}:
1.0
2.0
3.0
これと関連して、Make sure your activation and loss functions preserve the type of their inputs
に書いてあることではあるが、Float64 と Float32 の変換が起こらないようにする。
例えば、Float32 を使ってモデル構築をしているのに、leakyrelu の勾配を変更して
x->leakyrelu.(x, 0.2)
と書いてしまうと 0.2 の型が Float64 であるため、型の変換が行われて激烈に遅くなる。
x->leakyrelu.(x, 0.2f0)
とするのが良い。自分は最初これを知らず前者のように書いてしまい、一向に計算が終わらなくなってしまい時間を浪費した。
logitbinarycrossentropy に 0, 1 ではなく 0f0, 1f0を渡したのも同様の理由。
生成結果
MNISTを使って、バッチサイズ128、30エポック(14,000イテレーション)回した結果、
iterations = 0

iterations = 1,000

iterations = 2,500

iterations = 5,000

iterations = 10,000

iterations = 14,000 (最後)

アニメーション

損失関数
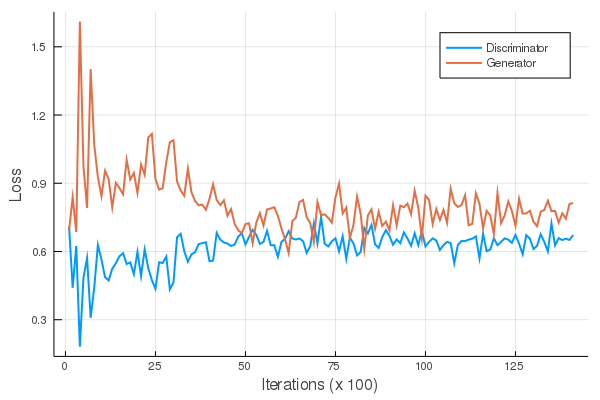
と数字っぽい画像が無事に生成できた。
まとめ
Google Colaboratory上でお気楽に環境やモデル構築ができるTensorflowに比べるとFlux.jlは環境構築やリファレンスの少なさで苦労することはあるかもしれないが、 開発はアクティブに行われているので、今後の発展が楽しみである。自分も、また色々試してみたい。